


Imagine spending MONTHS publishing new content, only to find that Google isn’t crawling or indexing these pages.
No first-page rankings. No organic traffic. Nothing.
In truth, this is rare. But it can happen.
Depending on the issue, it can take 5 minutes to fix, or 5 weeks.
This guide will help you diagnose any potential problems and (hopefully) help you fix them.
Here's what we'll be covering:
- What is crawlability?
- Common crawlability issues
- How to check if a page is crawlable
- Crawling and indexing checklist
- How to improve crawlability
What is crawlability?
Crawlability is the search engine's ability to find and crawl content on your website. If the bot finds crawlability issues like broken links, server errors, looped redirects, robots.txt blocking issues, or lack of internal links, your site’s crawlability is considered poor.
Fixing crawlability issues is crucial as it’s the foundation of your website’s technical SEO. Without it, your website won’t fully benefit from other SEO efforts like publishing new web pages, blog posts and acquiring backlinks.
Common crawlability issues
In truth, there are lots of factors that can impact your site’s crawlability, but here are the most common.
Site structure and internal links
How you organise your website’s content is the most important factor when optimising crawlability.
Site structure is the way your pages link with one another by using the site’s hierarchy and internal links.
Without an optimal site structure, web crawlers will have difficulty discovering pages that are low in the hierarchy, or are not linked to at all (these pages are called “orphaned pages”).
For example, a typical hierarchy might look similar to a pyramid. You have the homepage at the top and several layers underneath - these are your subpages.
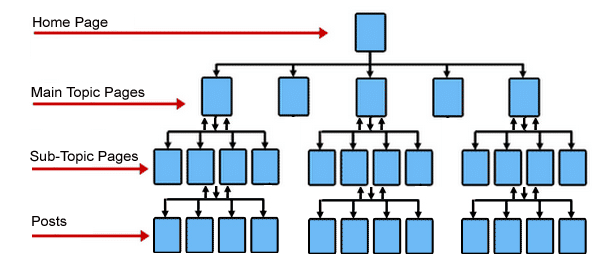
Hypothetically, Google then crawls the site from the top of the pyramid (the homepage) to the bottom.
The further away your pages are to the top, the harder they will be for the Googlebot to find. Especially if there are pages with no links pointing to them.
For best practice, get your important pages within three clicks from the homepage. Using a tool like Screaming Frog will allow you to see your site’s current structure and “crawl depth”.
Non-HTML links
If your links are contained within frames, JavaScript or Flash, then they may not be getting indexed and crawled.
You should compare Google’s text-only version of your page with the full page.
Here’s how:
Find your page in the SERP (search engine results page) and click the three dots next to the URL.
This will bring up the “About this result” box. At the bottom right, click “Cached”.

Select the “Text-only version” link at the top of the page. That’s it!

If the links do not appear in the cached text, then Google may not be crawling them.
In general, formatting links to be text or image-based should be the goal. You should always avoid using unspiderable JavaScript or Flash links.
Server errors
Server errors, like 502 errors, will prevent crawlers from accessing all of your website’s content. Google Search Console reports 5xx server errors, which means the Googlebot wasn’t able to access the page, it timed out, or the site was too busy.
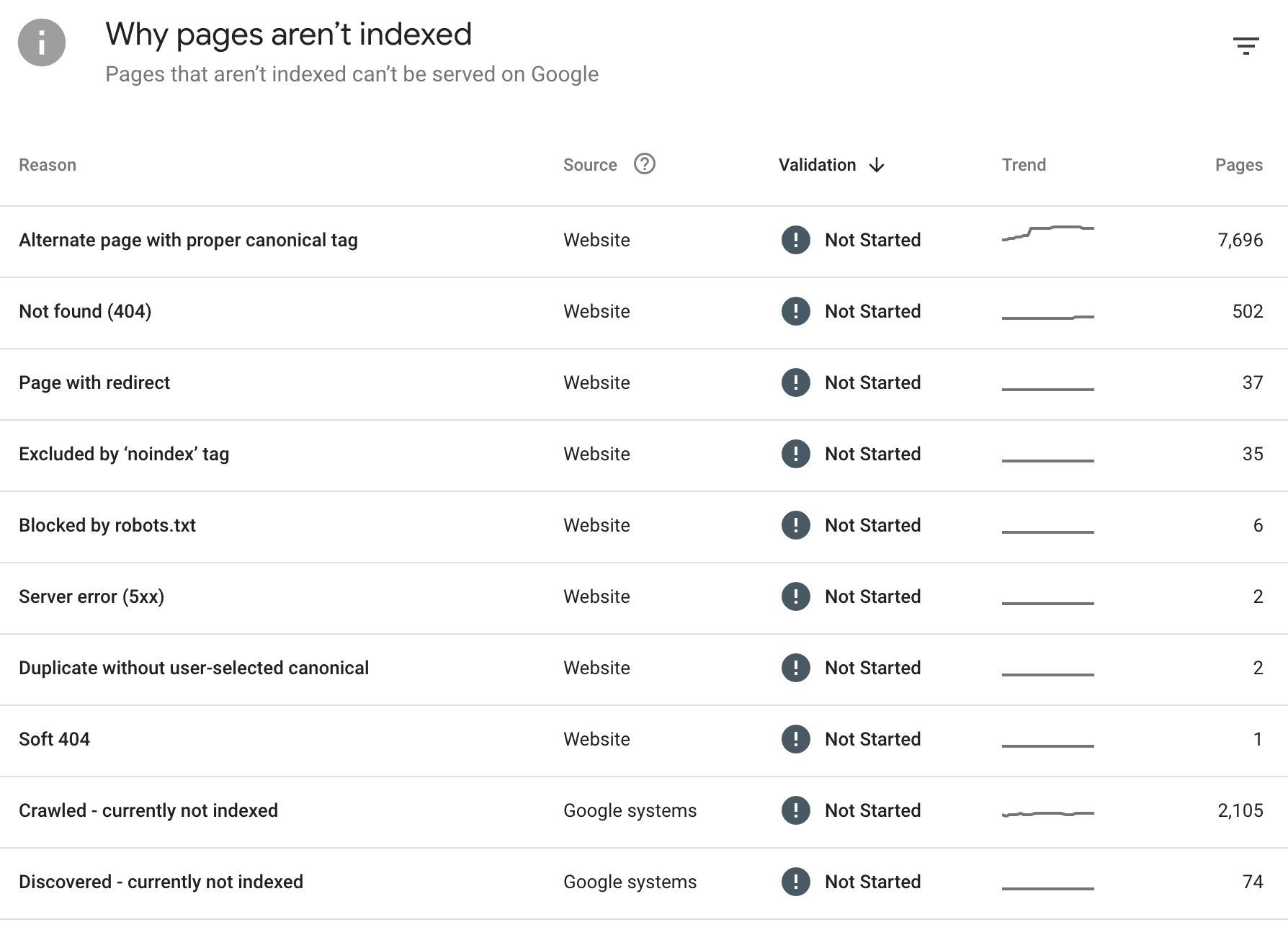
An overloaded server will likely stop responding to crawler (and user) requests, meaning they will “time out” and not crawl the page.
Redirects
Redirect issues, like looped redirects, will stop crawlers from crawling. For example, we have come across URLs that are redirected to one another, meaning the crawler cannot crawl either page in the loop.
We also see multiple redirect chains, i.e. page redirected > page redirected > page redirected > live page. This should also be avoided.

You can use a tool like HTTP Status Checker to analyse bulk URLs to find redirecting issues quickly.
Sitemaps
A sitemap is crucial for telling Google which pages you think are important on your site. Search engine crawlers read the sitemap in order to efficiently crawl your site.

When an XML sitemap is submitted to Google, any issues are usually flagged.
However, you should also analyse the sitemap to ensure all important pages are included within it, if there are any pages that shouldn’t be included, and if there are no server errors on the /sitemap.xml URL that may prevent crawlers from accessing it.
Blocking access
The robots.txt file is the first file of your website that crawlers look at. In this file, you can deliberately block crawlers from accessing the pages on your site.
For example, you might want to block a page from public access, so it’s not indexed. Or you may block crawlers from finding a staging site where you’re working on your new website.
But if there are any mistakes, it can cause mass-deindexing and prevent crawlers from accessing all, or a section, of your website.
Unfortunately, we’ve seen cases of developers forgetting about this code on the staging site. The new site is put live, but search engines are not able to crawl and index it.
Visit your robots.txt file and look out for the dreaded:
User-agent: *
Disallow: /
Or it may look like the below if a section of the site is blocked:
User-agent: *
Disallow: /blog/
Crawl budget
Crawl budget is the number of pages Google crawls and indexes within a given timeframe. If the number of pages you have on your website exceeds your crawl budget, you will have pages that aren’t indexed.

It’s important to note that most websites don’t need to worry about crawl budget. You should only really pay attention to it if:
- You have a large website with thousands of pages. Google may have trouble finding them all.
- You have just added lots of pages. You should make sure you have the crawl budget to get them indexed quickly.
- You have lots of redirects with pages on your website. These redirect chains can use a lot of your crawl budget.
How to check if a page is crawlable
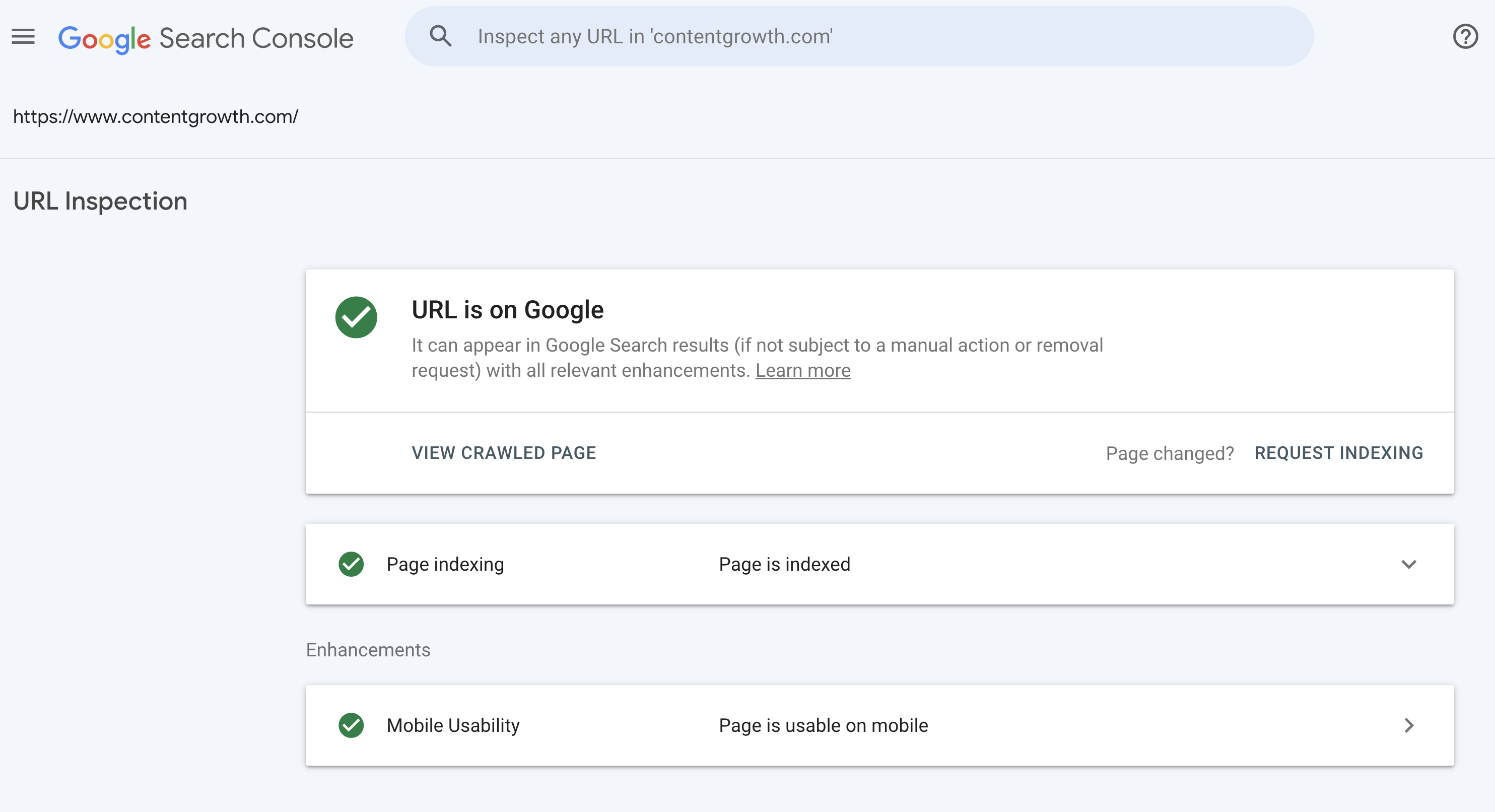
The best way to check if a page is crawlable is to use the "URL Inspection" tool in Google Search Console. Simply enter the URL you want to check and read the report.
If your page has already been crawled and indexed, you will see a green tick.
If your page has crawling and indexing issues, you will see grey instead.
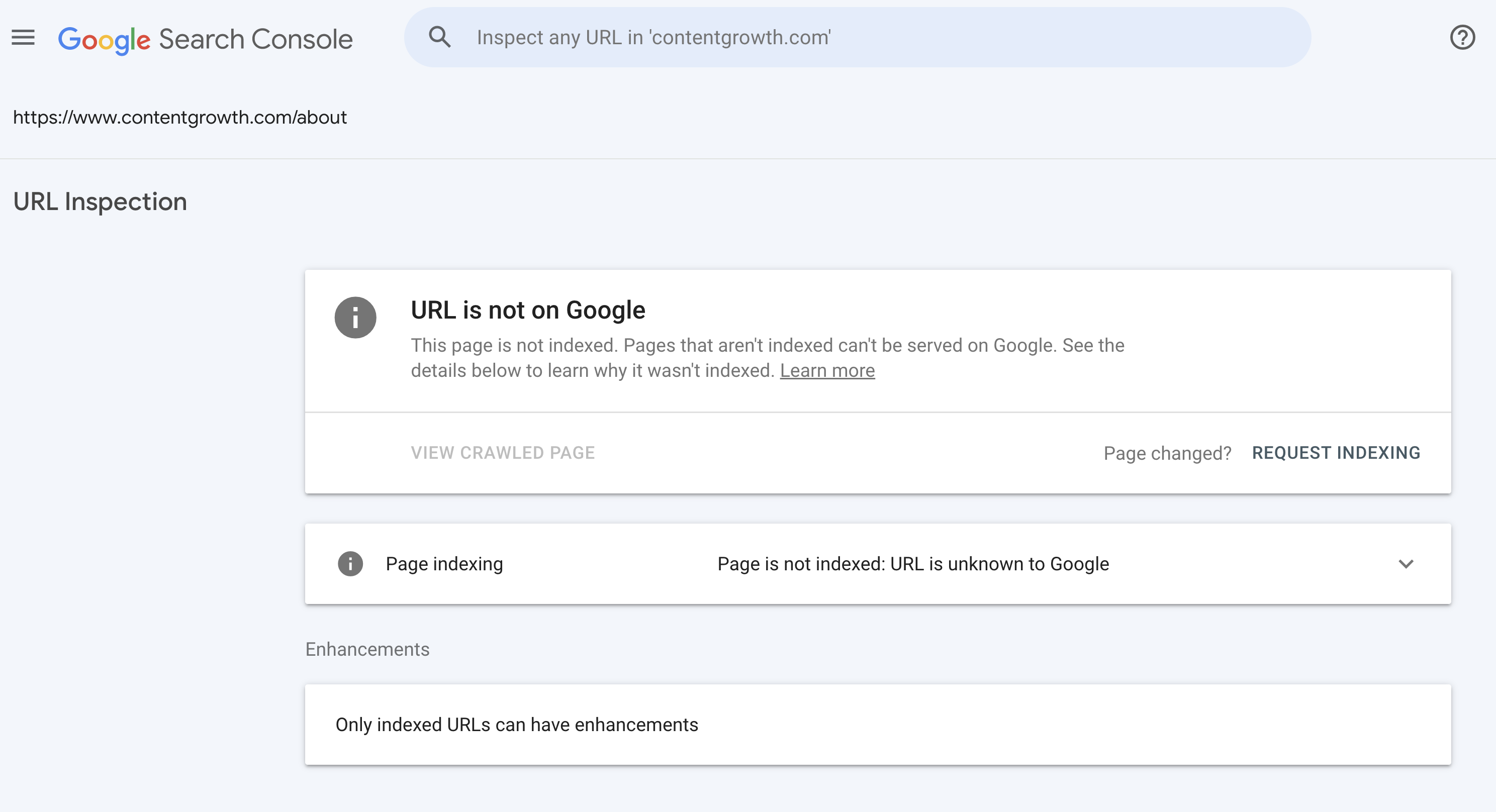
The ‘Page indexing’ box will tell you the issues Google has found for the page.
In this case, we have checked a page that doesn’t exist on our website, so the error “Page is not indexed: URL is unknown to Google” makes sense.
However, you may see other issues such as “Page is not indexed: Duplicate, Google chose different canonical than user”, as we have for a client.
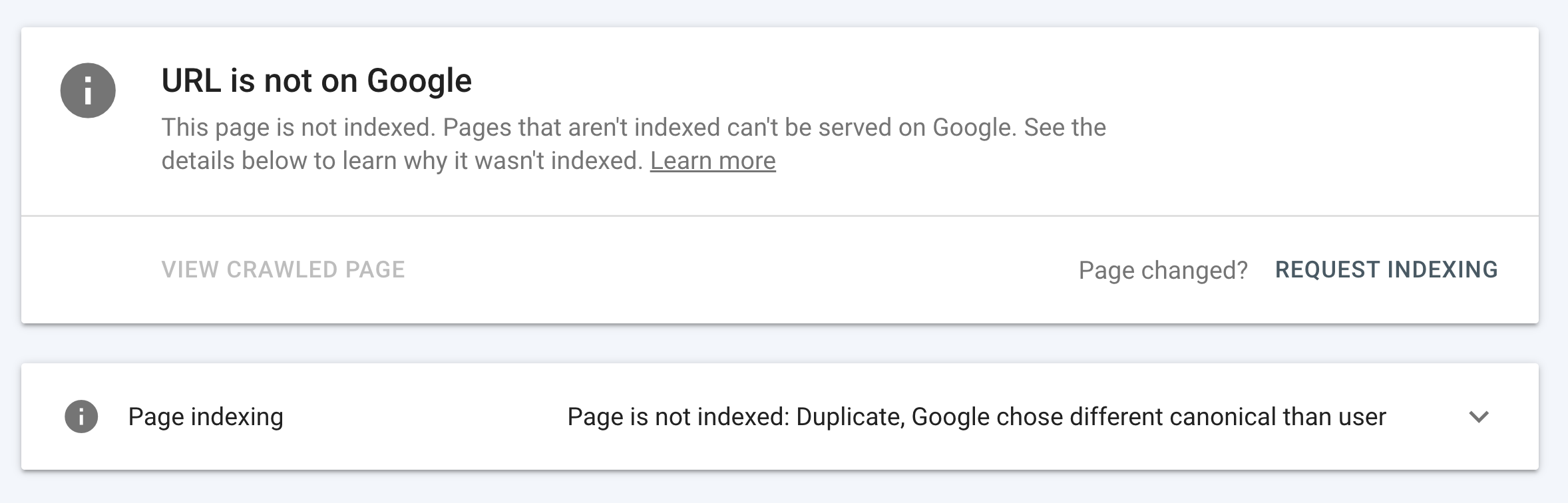
To analyse the issue in more detail, open the ‘Page indexing’ box. Here you will see information about:
- Discovery: How Google found the page.
- Crawl: When it was last crawled, is it able to crawl the page, and more.
- Indexing: The user-generated and Google-selected canonical URLs.
In the example with our client, we can see the crawlability of the page is fine.

But Google has selected a different canonical URL to the user-generated URL. Meaning Google thinks the page is the same as another page on the website, which makes the page non-indexable.
Now we have found the issue, we can make changes to the pages to fix the issue, recrawl and (hopefully) index the page.
How to test sitewide crawlability
The best way to test a website’s crawlability at scale is to use a website crawling tool such as Screaming Frog, Site Bulb or Deep Crawl. These tools will flag obvious crawling and indexing issues out of the box.
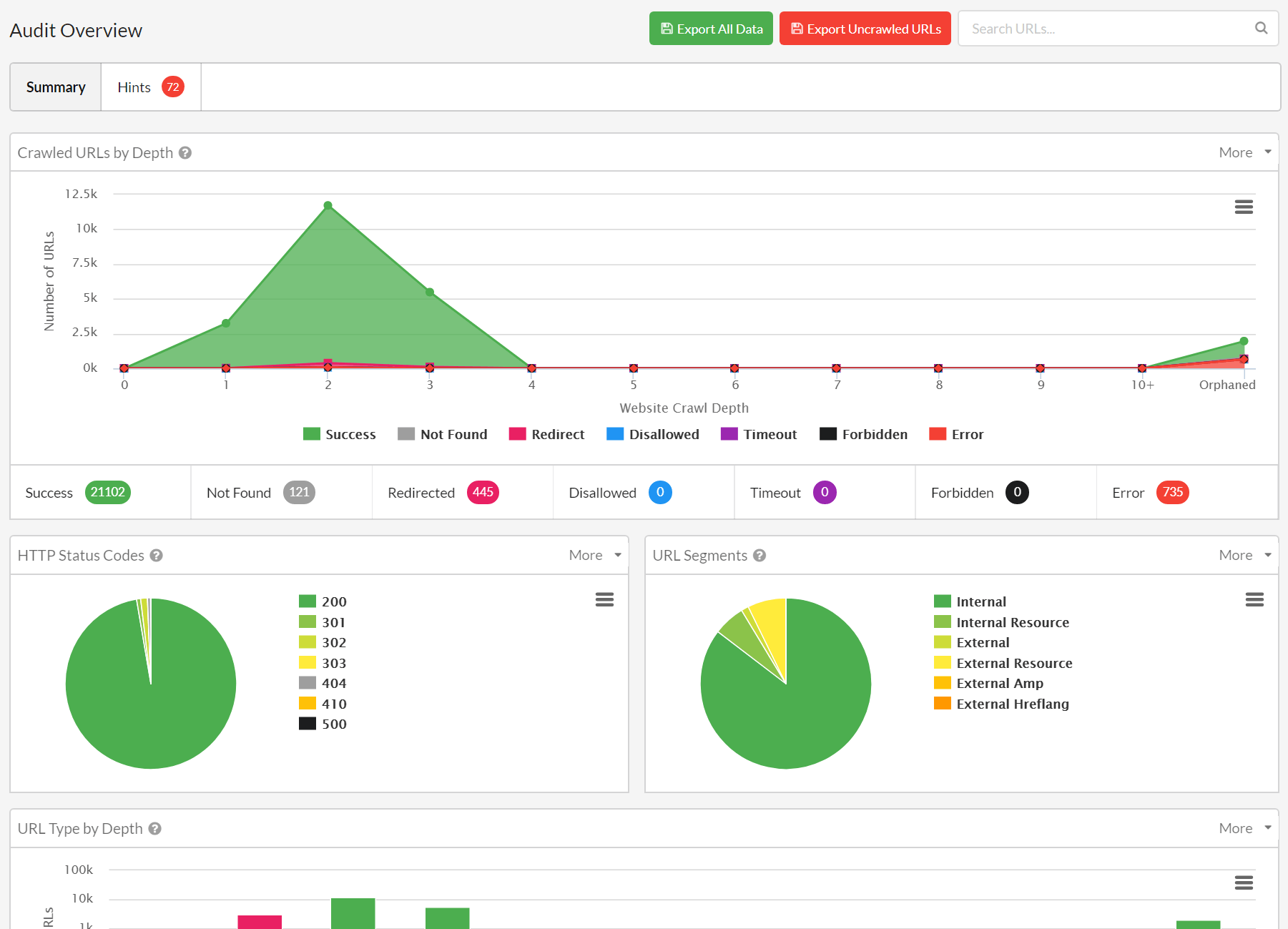
To find issues and opportunities that these third-party tools don’t/can’t flag, you should manually check specific aspects of your website, the crawl output (i.e. spreadsheet export), and by using other tools.
Crawling and indexing checklist
Using the information and tools we’ve discussed, here’s a checklist to identify issues and improve the crawlability of your site.
Robots.txt file
As we’ve already discussed, check your robots.txt file to see if you are blocking any pages from being crawled.
You can normally find this by going to the following URL for your website:
domain.com/robots.txt
This is what it looks like if your site is blocked from being crawled:
User-agent: *
Disallow: /
And this is what it looks like the below if a section of the site is blocked:
User-agent: *
Disallow: /blog/
XML sitemap(s)
Firstly, make sure you have a sitemap, and it’s submitted to Google.
You can normally find the sitemap by going to the following URL for your website:
domain.com/sitemap.xml
Check Google Search Console to see if there are any issues being reported.
You should also analyse your sitemap to ensure:
- all important pages are included within it
- there aren’t any pages that shouldn’t be included
- there are no server errors on the /sitemap.xml URL that may prevent crawlers from accessing it.
Site structure
Use a site architecture/crawl visualisation tool like Screaming Frog to see the structure of your website.
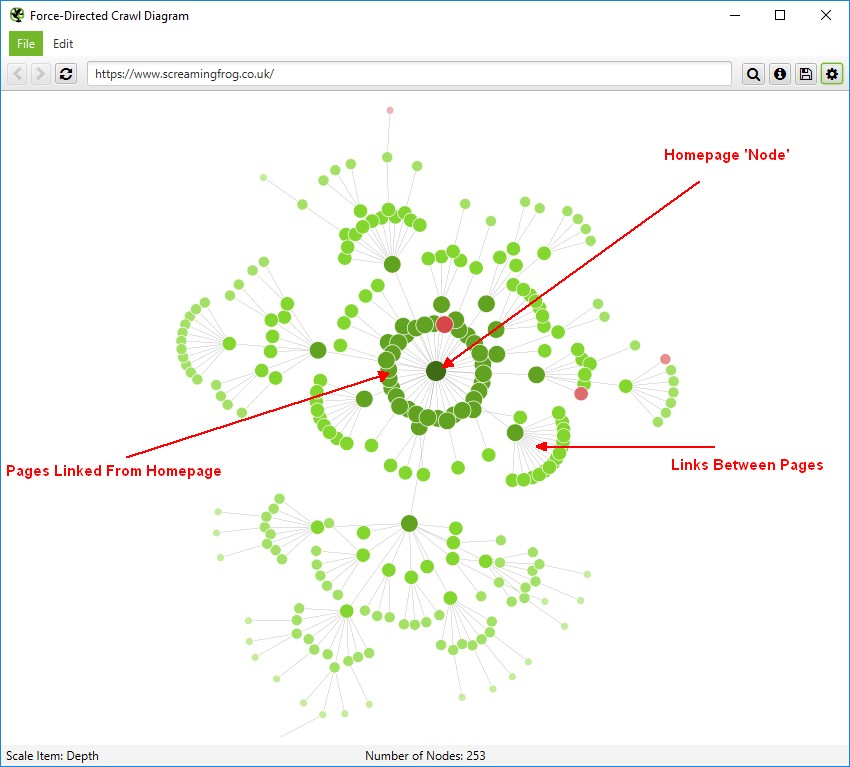
Visualisations can help provide perspective or reveal underlying patterns that are harder to uncover in data and spreadsheets.
Orphaned pages
Find pages that are not being linked to from other pages on your site.
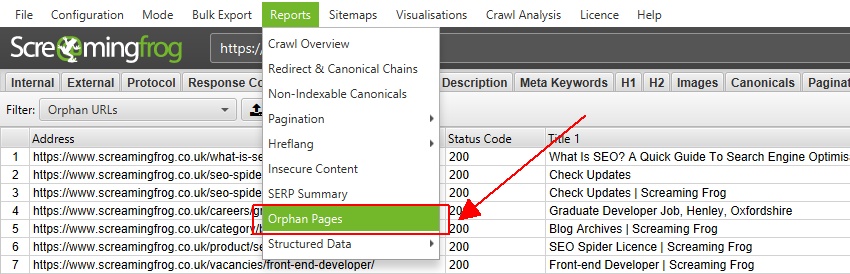
Here’s Screaming Frog’s guidance on finding orphaned pages using their tool:
- Select ‘Crawl Linked XML Sitemaps’ under ‘Configuration > Spider > Crawl’
- Connect to Google Analytics under ‘Configuration > API Access’
- Select ‘Crawl New URLs Discovered In Google Analytics’
- Connect to Google Search Console under ‘Configuration > API Access’
- Select ‘Crawl New URLs Discovered In Google Search Console’
- Crawl the website
- Click ‘Crawl Analysis > Start’ to populate orphan URLs filters
- Analyse ‘Orphan URLs’ filters under sitemaps, analytics and Search Console tabs
- Export combined orphan URLs via ‘Reports > Orphan Pages’
- Bonus: Identify orphan pages in the internal tab via blank crawl depth
Internal links
We want to fix any existing issues and optimise our internal link structure.
For example:
- Make ‘nofollow’ internal links ‘dofollow’
- Fix or remove any broken links
- Link to important pages that lack internal links

Status codes
Check the status codes of all the pages on your site. Any showing “200 – OK” are reporting no issues.
But here’s a list of status codes you should look out for:
- 0 – Blocked By Robots.txt
- 0 – DNS Lookup Failed
- 0 – Connection Timeout
- 0 – Connection Refused
- 0 – Connection Error / 0 – No Response
- 301 – Moved Permanently / 302 – Moved Temporarily
- 400 – Bad Request / 403 – Forbidden / 406 – Status Not Acceptable
- 404 – Page Not Found / 410 – Removed
- 429 – Too Many Requests
- 500 – Internal Server Error / 502 – Bad Gateway / 503 – Service Unavailable
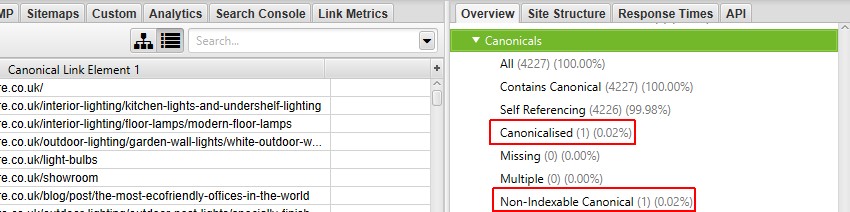
Noindex and canonical tags
Noindex and canonical tags impact how Google indexes (or doesn’t indexes) pages on your website.
In short, a ‘noindex’ tag simply tells Google not to index the page. The tag could look something like:
<meta name="robots" content="noindex"/>
A canonical tag tells Google that a specific URL represents the master copy of a page, i.e. it’s a duplicate of another page. This means Google will only index the master version. The tag could look something like:
rel=”canonical”
Tools like Screaming Frog make it extremely easy to find these tags.
Crawl stats report
Check Google Search Console’s “Crawl stats’ report and look for anything that can be improved.
In the “Crawl requests breakdown”, you will see how your crawl budget is being used.
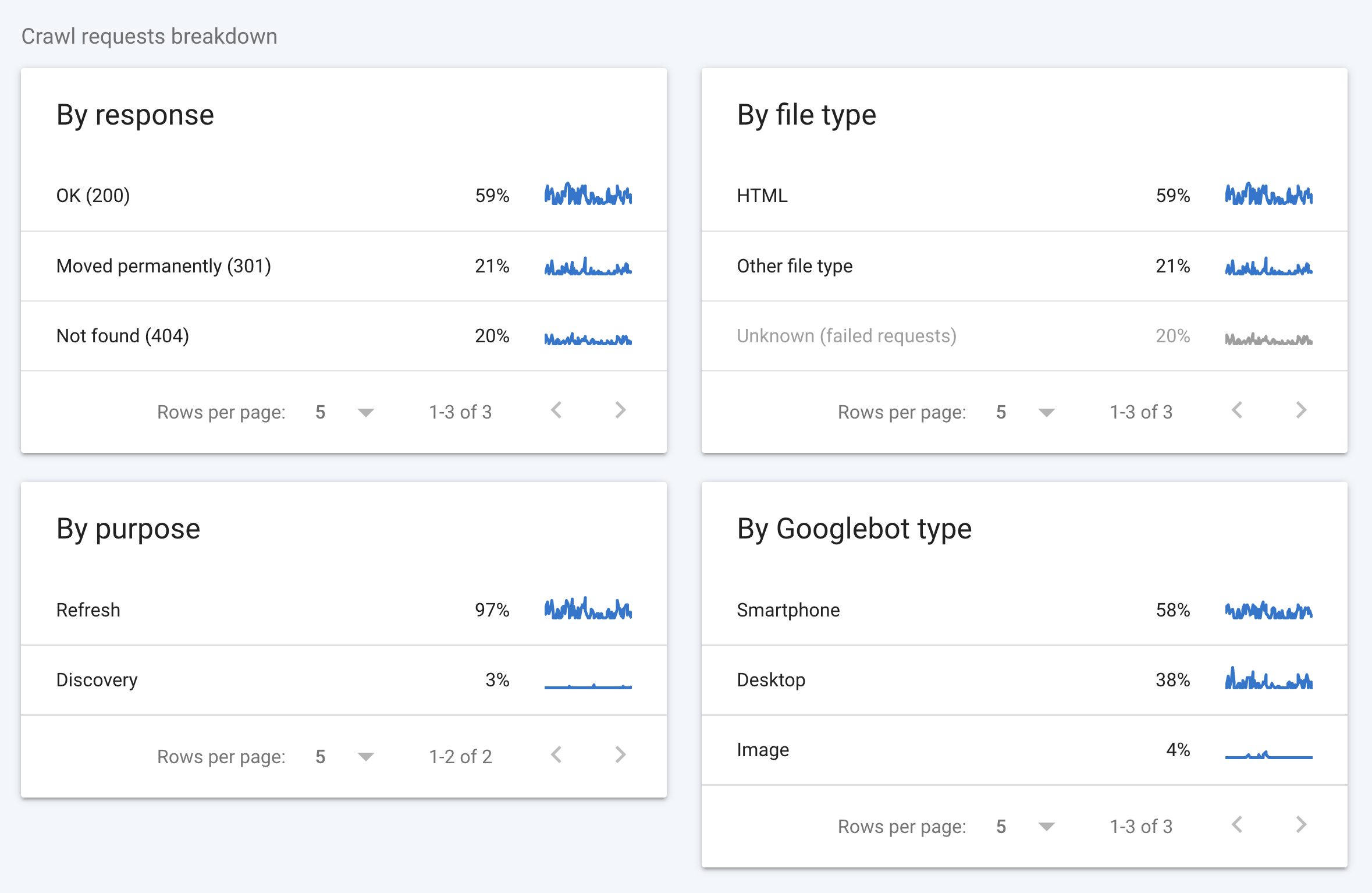
We can see from the above that 41% of the crawl requests are going to 301 and 404 pages, which is an unnecessary use of the crawl budget.
Again, it’s important to note that this is really important for larger websites.
How to improve crawlability
To recap, here’s how to optimise the crawlability of your website:
- Check there are no issues with your robots.txt file
- Check there are no issues with your XML sitemap
- Optimise your website structure (internal links)
- Fix any links that aren’t normal (e.g. broken links)
- Fix any orphaned pages
- Fix pages with errors (status codes)
- Fix redirect loops
- Remove the noindex tag from pages that you want to index
- Remove the canonical tag from pages that you want to index
- Optimise your crawl budget (if a larger site)

